CSCI 312 Assignment #1
This assignment is a modified version of the Haskell warmup exercise from Prof. Michael Greenberg’s syllabus. I’ve included only those problems that I was able to complete in a reasonable amount of time. If you’re feeling ambitious, you might try some of the omitted problems for extra credit. Following Prof. Greenberg’s convention, I’ve used undefined to indicate the code you need to write yourself.
Problem 1: natural recursion
Please don’t use any Prelude functions to implement these—just write natural recursion, like we did in class.
Write a function called sumUp that sums a list of numbers.
sumUp :: [Int] -> Int
sumUp [] = undefined
sumUp (x:xs) = undefinedWrite a function called evens that selects out the even numbers from a list. For example, evens [1,2,3,4,5] should yield [2,4]. You can use the library function even.
evens :: [Int] -> [Int]
evens [] = undefined
evens (x:xs) = undefinedWrite a function called incAll that increments a list of numbers by one. You’ll have to fill in the arguments and write the cases yourself.
incAll :: [Int] -> [Int]
incAll = undefinedNow write a function called incBy that takes a number and increments a list of numbers by that number.
incBy :: Int -> [Int] -> [Int]
incBy = undefinedWrite a function append that takes two lists and appends them. For example, append [1,2] [3,4] == [1,2,3,4]. (This function is called (++) in the standard library… but don’t use that to define your version!)
append :: [Int] -> [Int] -> [Int]
append = undefinedProblem 2: data types
Haskell (and functional programming in general) is centered around datatype definitions. Here’s a definition for a simple tree:
data IntTree = Empty | Node IntTree Int IntTree deriving (Eq,Show)Write a function isLeaf that determines whether a given node is a leaf, i.e., both its children are Empty.
isLeaf :: IntTree -> Bool
isLeaf Empty = undefined
isLeaf (Node l x r) = undefinedWrite a function sumTree that sums up all of the values in an IntTree.
sumTree :: IntTree -> Int
sumTree = undefinedWrite a function fringe that yields the fringe of the tree from left to right, i.e., the list of values in the leaves of the tree, reading left to right.
For example, the fringe of Node (Node Empty 1 (Node Empty 2 Empty)) 5 (Node (Node Empty 7 Empty) 10 Empty) is [2,7].
fringe :: IntTree -> [Int]
fringe = undefinedProblem 3: binary search trees
Write a function isBST to determine whether or not a given tree is a strict binary search tree, i.e., the tree is either empty, or it is node such that:
-
- all values in the left branch are less than the value of the node, and
- all values in the right branch are greater than the value of the node,
- both children are BSTs.
Problem 4: map and filter
We’re going to define each of the functions we defined in Problem 1, but we’re going to do it using higher-order functions that are built into the Prelude. In particular, we’re going to use map, filter, and the two folds, foldr and foldl. To avoid name conflicts, we’ll name all of the new versions with a prime, '.
Define a function sumUp' that sums up a list of numbers.
sumUp' :: [Int] -> Int
sumUp' l = undefinedDefine a function evens' that selects out the even numbers from a list.
evens' :: [Int] -> [Int]
evens' l = undefinedDefine a function incAll' that increments a list of numbers by one.
incAll' :: [Int] -> [Int]
incAll' l = undefinedDefine a function incBy' that takes a number and then increments a list of numbers by that number.
incBy' :: Int -> [Int] -> [Int]
incBy' n l = undefinedProblem 5: defining higher-order functions
We’re going to define our own versions of the map and filter functions manually, using only natural recursion and folds—no using the Prelude or list comprehensions. Note that I’ve written the polymorphic types for you.
Define map1 using natural recursion.
map1 :: (a -> b) -> [a] -> [b]
map1 = undefinedDefine filter1 using natural recursion.
filter1 :: (a -> Bool) -> [a] -> [a]
filter1 = undefinedProblem 6: Maybe and Either
Python and Java allow for null values (None in Python and null in Java) as a convenient way of indicating the absence of a result. In a famous 2009 lecture, computer scientist Tony Hoare (inventor of Quicksort) called the use of such values a Billion Dollar Mistake, citing the hidden costs that they can incur by allowing you to ignore exceptional situations.
Instead of relying on null values, Haskell provides a special datatype called Maybe. This datatype allows you to “wrap” a result value in a way that forces you to deal with exceptional situations.
Consider, for example, the classic square-root function, which is defined only for non-negative numbers. In Java or Python, passing a negative value to such a function would be handled by throwing (raising) an exception. In Haskell, by contrast, we could make this function return the type Maybe Float, defined as:
data Maybe Float = Nothing | Just FloatValues of the type Maybe a can be Nothing or Just x, where x is a value of type a. Note that Maybe is polymorphpic: we can choose whatever type we want for a, e.g., Just 5 :: Maybe Int, or we can leave a abstract, e.g., Just x :: Maybe a iff x :: a.
Write a function sqrt' that returns Just x if its input value x is non-negative, and returns Nothing otherwise:
sqrt' :: Float -> Maybe Float
sqrt' = undefinedThe test code for this function will use Haskell’s mapMaybe function to ignore Nothing results in a list of numbers when computing their square roots.
This trick – using a dataype to handle exceptional situations – also comes in handy when you want to report an exceptional situation without resorting to an exception. For example, consider another classic “gotcha”, divide-by-zero. For reporting a divide-by-zero, we might want to have function that returns the result of a division if the denominator is non-zero, and returns an error message (string) otherwise. Haskell’s Either datatype supports this:
data Either a b = Left a | Right bTypically, the error result (e.g., an error message) is associated with the Left option, and the non-error result is associated with the Right option (presumably because right also means correct.)
To finish this problem, write a function div’ that returns either an error message or correct value, depending on whether its second input is zero:
div' :: Float -> Float -> Either String FloatProblem 7: Creating polymorphic datatypes
Haskell’s Maybe and Either are polymorphic datatypes; i.e., they support working simultaneously with values of different types. You are already familiar with polymorphic types from Python, in the form of tuples. Like Python, Haskell has a tuple datatype that allows us to aggregate values: values of type (a,b) will have the form (x,y), where x has type a and y has type b.
Write a function swap that takes a pair of type (a,b) and returns a pair of type (b,a).
swap :: (a,b) -> (b,a)
swap = undefinedWrite a function pairUp that takes two lists and returns a list of paired elements. If the lists have different lengths, return a list of the shorter length. (This is called zip in the prelude. Don’t define this function using zip!)
pairUp :: [a] -> [b] -> [(a,b)]
pairUp = undefinedWrite a function splitUp that takes a list of pairs and returns a pair of lists. (This is called unzip in the prelude. Don’t define this function using unzip!)
splitUp :: [(a,b)] -> ([a],[b])
splitUp = undefinedWrite a function sumAndLength that simultaneously sums a list and computes its length. You can define it using natural recursion or as a fold, but—traverse the list only once!
sumAndLength :: [Int] -> (Int,Int)
sumAndLength l = undefined
Problem 8: maps and sets
Like Python, Haskell has many convenient data structures in its standard library. In this problem we’ll be working with sets and maps. Data.Map (like Python dictionary) and Data.Set (like Python sets). Specifically, we’ll use maps and sets to code up the directed acyclic graph (DAG) structure that you learned about in CSCI 112. The code shown in the instructions below is already written for you in the Hw01.hs file you downloaded, so for now you can just read over the code below and make sure you understand it.
We can start by defining what we mean by the nodes of the DAG: we’ll have them just be strings. We can achieve this by using a type synonym.
type Node = StringTo create a Node, we can use the constructor, like so:
a = "a"
b = "b"
c = "c"
d = "d"
e = "e"We can define a DAG now as a map from Nodes to sets of Nodes. The Map type takes two arguments: the type of the map’s key and the type of the map’s value. Here the keys will be Nodes and the values will be sets of nodes. The Set type takes just one argument, like lists: the type of the set’s elements.
type DAG = Map Node (Set Node)Let’s start by building a simple DAG g to represent the graph below:
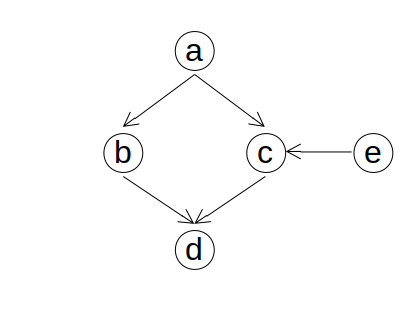
g = Map.fromList [(a, Set.fromList [b,c]),
(b, Set.fromList [d]),
(c, Set.fromList [d]),
(d, Set.fromList []),
(e, Set.fromList )]Now write a function hasPath that takes a DAG and two nodes and returns True if there is a path from the first to the second in the DAG:
hasPath :: DAG -> Node -> Node -> Bool
To write this function I implemented a simple algorithm: if the second node is a member of the first node’s neighbors, return True; otherwise, recur on each of the neighbors and the second node and return whether any of the results is True. To support this algorithm I found it useful to write the following two helper functions:
neighbors :: DAG -> Node -> Set.Set Node
any' :: Set.Set Bool -> Bool
The neighbors function returns the neighbors of a node, and the any' function returns True if any members of a set are True, and False otherwise.